研究センターレポート
予防医学、セルフメディケーション推進に向けたスクリーニング検査評価の最適化
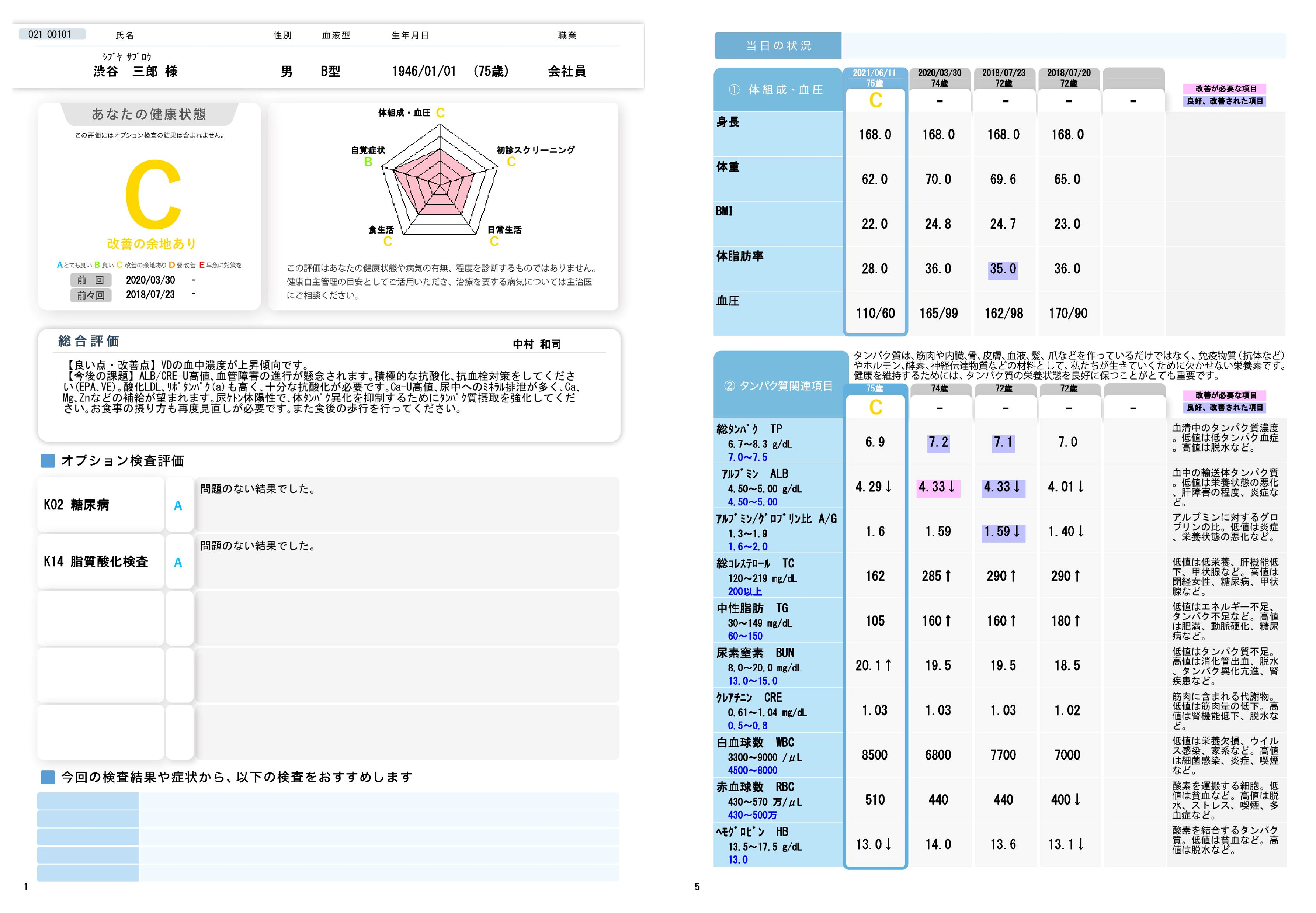
2023年5月にKYBメディカルサービス社が提供するメディカルレポートがリニューアルいたしました。
メディカルレポート K01初診スクリーニングと呼ばれる69項目の血液検査の結果と心身の自覚症状、生活習慣、身体測定の結果をもとに、足りない栄養素を浮き彫りにし、医師・管理栄養士からの生活習慣の改善指導や栄養アドバイスをレポートにするサービス
リニューアルの内容は以下の通りです。
検査結果の解析の精度を向上させ、10項目(タンパク質関連項目・血糖関連項目・脂質関連項目・・・・・・など)に分類した内容について、それぞれをA~Eの5段階で評価
次に、項目間の関連を考慮した上で、医師が診療上重要視する項目に着目した評価
さらに、主観を除くためにAI技術を用いて多面的な評価計算
これらの評価により、血液検査と疾患のリスクを明らかにすることでき、医師・管理栄養士による生活習慣や食生活のより細かなアドバイスをすることで、予防医療やセルフメディケーションを促進させることが可能になります。
研究センターでは、このA~Eの5段階評価に対しての妥当性検証を行い、2023年5月の日本臨床検査医学会学術集会で口演発表を行いました。
今回の研究レポートではその研究発表の内容について解説させていただきます!
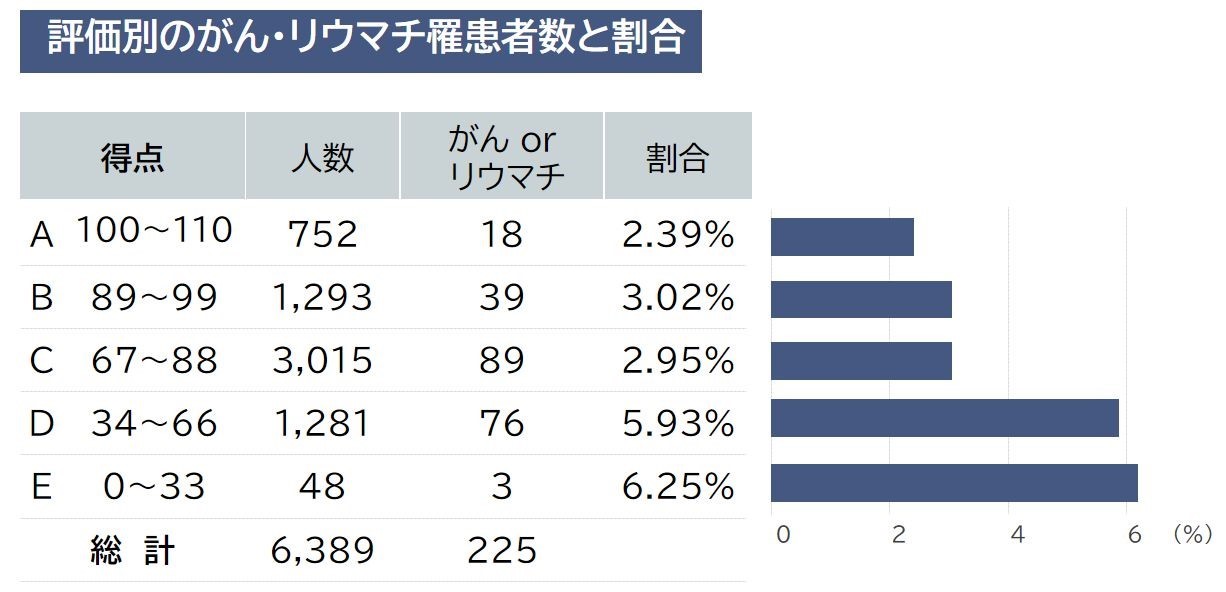
タンパク質関連項目の評価が低いとがん・リウマチになりやすい
2021年1月~2023年4月にK01初診スクリーニング検査(血液検査59、尿検査8、唾液検査2)を受検した6,399人を対象に、タンパク質関連項目の得点に応じてA~Eの5段階に分類しました(満点は、110点)。
その結果、評価Aの人数が752人、そのうち、検査時にがん・リウマチに罹患していた方が18人(2.39%)いました。
一方、評価Dの人数は1,281人で、そのうちガン・リウマチに罹患している方は76人(5.93%)いました。
がん・リウマチの罹患率と5段階評価に関係があることは明らかです。
そこで、Jonckheere-Terpstra 検定を用いて検定を行ってみました。
結果、がんにおいてはP-value=0.001477、リウマチにおいてはP-value= 0.003344となり、評価とがん・リウマチ罹患率には、有意に関連があることが認められました。
Jonckheere-Terpstra 検定 3群以上の群で、単調に増加する・減少する、などの傾向を検定するノンパラメトリックな検定法。
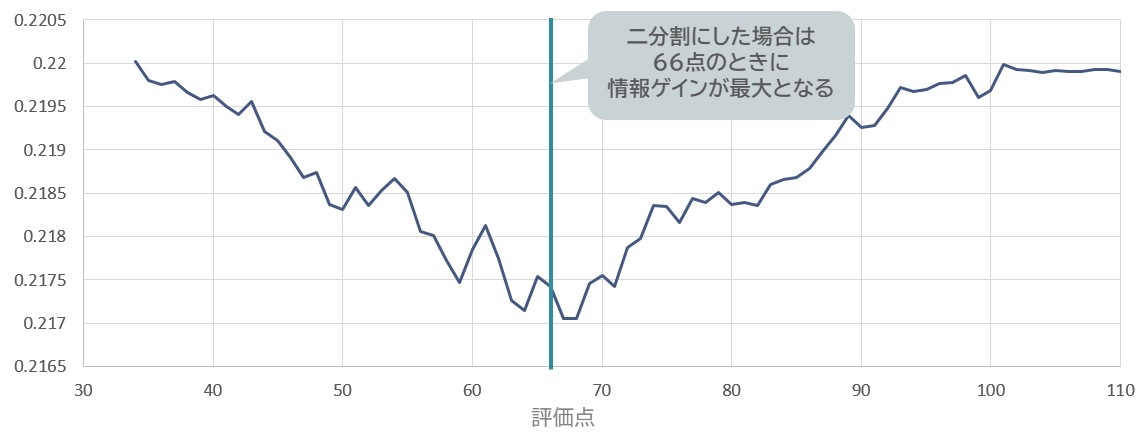
タンパク質関連項目を“〇”か“×”で評価すると…?
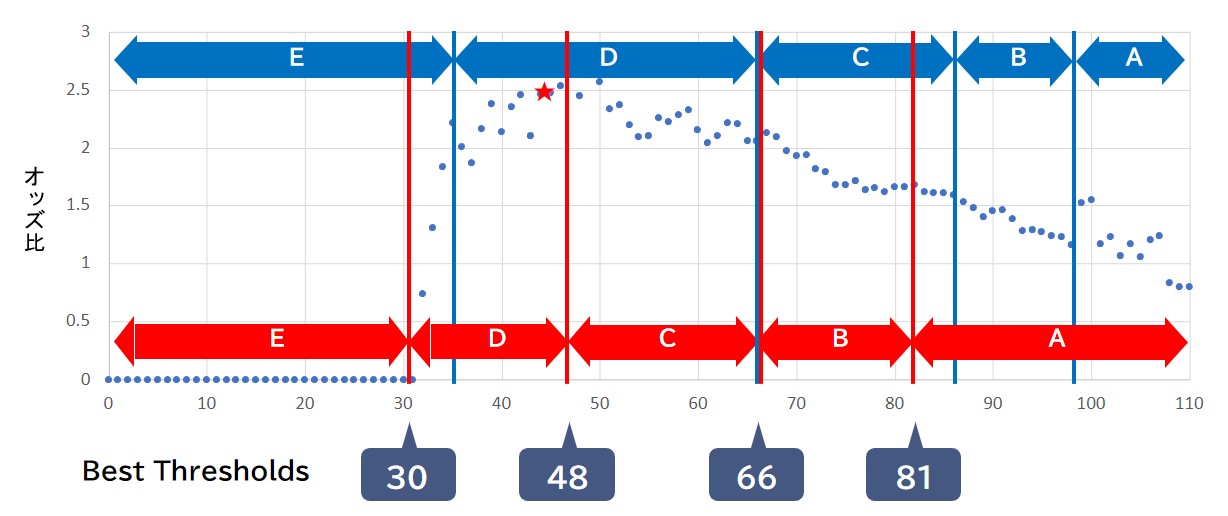
タンパク質関連項目を“〇”か“×”で評価するとしたら、グラフを見る限り、CとDの境界である66点付近に閾値があると考えられます。
これを裏付けるために、“情報論に基づいた計算”を行いました。
“情報論に基づいた計算”とは、ある得点を閾値として“〇”か“×”に分割した際、分割前後の情報エントロピーの減少量を測定する方法です。この減少量が大きいほど、より効果的な分割であると考えられます。
情報エントロピーとは 情報エントロピーは、情報の予測不可能性を表す指標です。 情報源(今回の場合はA~E評価)から出力される情報が予測可能である場合、エントロピーは低くなります。 反対に、予測不可能である場合には、エントロピーは高くなります。
計算の結果、エントロピーの減少量が最大(=情報ゲインが最大)となるのは、得点が66点のポイントであることが分かりました。※30点以下は有病者がいなかったため閾値の範囲から除外
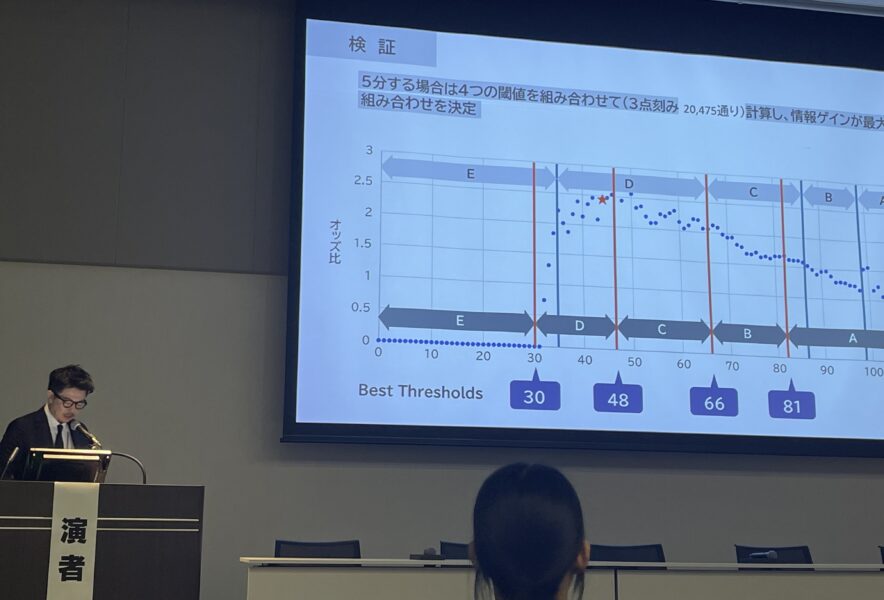
評価を5分割してみよう!
メディカルレポートはA~Eと5段階評価であるため、4つ閾値でエントロピーの減少量が最大となるポイントを決める必要があります。
しかし、全ての組み合わせを計算するには100万回以上計算しないといけません! そこで、今回は3点刻みで閾値を組み合わせ、計算を行いました。 (手動では数日かかってしまうので計算はPythonで行いました。Pythonコードは最下部でご参照ください!)
計算の結果、情報ゲインが最大となる閾値は(30, 48, 66, 81)のポイントであることが分かりました。
メディカルレポートでは66点以下が2分割、66点以上が3分割されていたのに対し、情報ゲイン計算の結果では66点以下が3分割、66点以上が2分割されているという違いが生じました。
予防医学としての評価
今回は情報論に基づいた計算を用いて検査結果を評価する方法を紹介しました。しかし、この方法が常に最適であるとは断言できません。 例えば、得点が50点の場合、従来の分類ではD判定となりますが、情報論に基づく閾値判定ではC判定になります。スクリーニング検査の主目的は疾患の予防です。C判定とD判定では、受検者の解釈やその後の行動が大きく異なると思われます。そのため、評価が受検者に予防的な行動を促すことは、予防医学の観点から非常に重要だと私たちは考えています。
今後もスクリーニング検査に関する研究を継続していきますので、引き続きご期待ください!
参考:Pythonコード
import numpy as np
import pandas as pd
from itertools import combinations
data = pd.read_csv('XXXX.csv')
df = pd.DataFrame(data)
# エントロピーを計算する関数
def entropy(probs):
return -np.sum([p * np.log2(p) for p in probs if p > 0])
# 情報ゲインを計算する関数
def information_gain(df, parent_entropy, thresholds):
# スコアに基づいてデータをソート
sorted_df = df.sort_values('score')
# 分割されたグループのリストを作成
groups = np.split(sorted_df, [sorted_df['score'].searchsorted(t, side='right') for t in thresholds])
# 各グループのエントロピーを計算し、データセット全体のエントロピーを計算
total_entropy = sum((group.shape[0] / df.shape[0]) * entropy(group['disease'].value_counts(normalize=True)) for group in groups if group.shape[0] > 0)
# 情報ゲインを計算
return parent_entropy - total_entropy
# 最適な閾値を探すための関数
def find_best_thresholds(df, num_thresholds, step):
best_thresholds = []
best_info_gain = float('-inf')
# 元のデータセットのエントロピー
original_entropy = entropy(df['disease'].value_counts(normalize=True))
# 組み合わせで閾値を探す
for thresholds in combinations(range(30, df['score'].max() + step, step), num_thresholds):
current_info_gain = information_gain(df, original_entropy, thresholds)
if current_info_gain > best_info_gain:
best_info_gain = current_info_gain
best_thresholds = thresholds
return best_thresholds, best_info_gain
# 閾値を4つ探し、それを3点刻みで行う
thresholds, info_gain = find_best_thresholds(df, 4, 3)
print("Best Thresholds:", thresholds)
print("Best Information Gain:", info_gain)